According to the latest Gartner reports, businesses adopting Generative AI are well capable of achieving approximately 15.7% cost savings. Many companies are looking forward to adopting generative AI in some capacity and some are creating their own applications using it.
LangChain is a framework that integrates AI from large language models into data pipelines and applications. With LangChain one could develop a generative AI application with ease.
Why LangChain for Generative AI Application?
LangChain offers several advantages that make it attractive for building generative AI applications:
- Build Generative AI with Your Own Data: Unlike other frameworks, LangChain lets you create powerful applications using your company’s specific data.
- Empower Your Teams: Imagine your HR department building an on-boarding assistant that guides new employees and answers role-specific questions, all based on company policies.
- Avoid Common Pitfalls: While LangChain is user-friendly and it simplifies development, some pitfalls can still occur
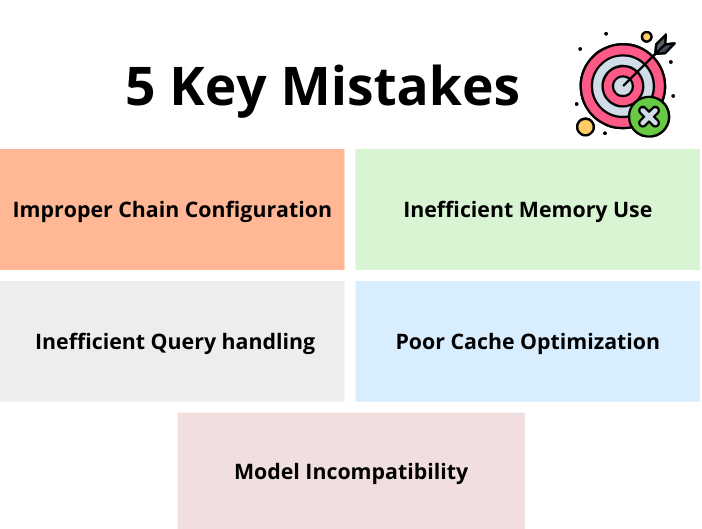
We'll explore 5 key Mistakes one should Avoid to ensure your generative AI application thrives.
1) Improper Chain Configuration
There is a proper chain which needs to be followed for an application, like configuring the model, then providing it with prompts and then the outcome, one cannot put outcome first in this chain, this could lead to improper chain configuration.
This leads to:
- Mismatched inputs & outputs causing misaligned input & output and unexpected results.
- Unintended data exposure, where sensitive information could accidentally be shared between components.
- Poor user experience due to frequent errors and crashes, reducing trust in the application.
To avoid this, you can follow certain precautions:
- Avoiding Incorrect chaining of components.
- Make sure that each step in the chain is correctly configured and compatible with the following steps.
- Remember to verify the data flow among the various components in the chain to avoid data mismatches or processing errors.
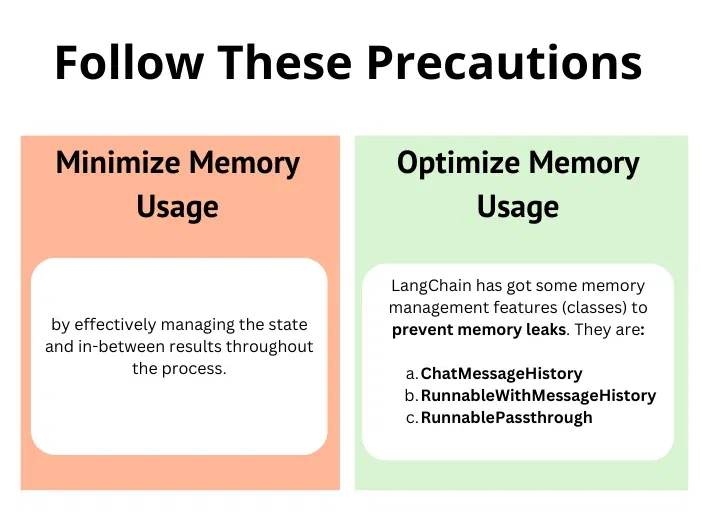
2) Inefficient Memory Use
LLMs are memory intensive, therefore suboptimal memory usage is another mistake that needs to be avoided. The memory of the model is for context understanding, so it needs only that much amount of memory depending on the questions it handles.
When there are variables stored and are not released, this consumes memory and does not allow necessary things to consume them, eventually leading the application to slow down.
3) Inefficient Query handling
LLMs function on user and system queries and they must be of the right length, not too short or too long. Long queries take up many tokens (charges apply for each token used).
Not handling queries well causes consumption of more resources to process the queries directly leading to a rise in cost for running the application.
To avoid this, you can follow certain precautions:
- Prevent inefficient query processing by optimizing your queries for both speed and relevance.
- Use LangChain’s query optimization techniques to improve performance and decrease response time. Some of them are:
- Query expansion: If an index is sensitive to how a query is phrased, you can create several paraphrased versions of the user’s question to improve our chances of getting a relevant result.
- Query routing: When you have multiple indexes and only some are useful for a given user input, you can direct the input to retrieve results only from the relevant indexes.
- Step back prompting: Sometimes search quality and model outputs can be thrown off by the details of a question. A solution is to first create a more general, “step back” question and then query using both the original and the step back question.
- Query structuring: If your documents have multiple attributes that can be searched or filtered, you can determine from any raw user question which specific attributes to use for searching or filtering.
- Hypothetical document embedding (HyDE): If you’re using a similarity search-based index, like a vector store, searching with raw questions might not work well because their embeddings may not closely match those of the relevant documents. Instead, it could be useful to have the model generate a hypothetical relevant document and then use that for the similarity search.
4) Poor Cache Optimization
You need to release memory of what you do not need upfront, this way you can keep cache optimization perfect.
Not managing cache can lead to increased latency in the application as it might need to regenerate content multiple times, causing delays in responding to user requests.
To avoid this, you can follow certain precautions:
- Avoid redundant computations by utilizing chancing mechanisms
- Use LangChain’s caching features to store and retrieve frequently used results to improve efficiency, these are:
- set_llm_cache
- InMemoryCache
- SQLiteCache
5) Model Incompatibility
LangChain is compatible with a wide range of LLM models like Llama 3, Mistral, Claud 3 GPT-3.5 & GPT-4. It is important for you to check the out-of-the-box compatibility.
If it is not compatible, it will be a slow and long process to customize everything in the existing framework.
To avoid this, you can follow certain precautions:
- Avoid using models that are not fully compatible with LangChain
- Make sure the models integrated into LangChain work well with the framework and are optimized for it.
Conclusion
All these 5 mistakes come with certain consequences which affect the application performance therefore becoming aware of these pitfalls is an important thing.
Avoid these mistakes with the mentioned precautions, then you can build high-performing generative AI applications with LangChain and use it to its full potential. It enables you to create innovative generative AI solutions, so use its features effectively for the best results.
Want to know more tips and uses of LangChain? Contact our experts today.
Drive Success with Our Tech Expertise
Unlock the potential of your business with our range of tech solutions. From RPA to data analytics and AI/ML services, we offer tailored expertise to drive success. Explore innovation, optimize efficiency, and shape the future of your business. Connect with us today and take the first step towards transformative growth.
You might also like
Stay ahead in tech with Sunflower Lab’s curated blogs, sorted by technology type. From AI to Digital Products, explore cutting-edge developments in our insightful, categorized collection. Dive in and stay informed about the ever-evolving digital landscape with Sunflower Lab.